Why we're leaving serverless

Every millisecond matters when you're in the critical path of API authentication. After two years of fighting serverless limitations, we rebuilt our entire API stack and slashed the end-to-end latency.
When we launched our API on Cloudflare Workers, it seemed like the perfect choice for an API authentication service. Global edge deployment, automatic scaling, and pay-per-use pricing. What's not to love?
Fast forward, and we've completely rebuilt it using stateful Go servers. The result is a 6x performance improvement and a dramatically simplified architecture that enabled self-hosting and platform independence.
TL;DR:
- Moved from Cloudflare Workers to Go servers
- Lowered latency by 6x
- Eliminated complex caching workarounds and data pipeline overhead
- Simplified architecture from distributed system to straightforward application
- Enabled self-hosting and platform independence
Here's the story of why we made this move, the problems that forced our hand, and what we learned along the way.
The Performance Wall We Hit
When developers integrate Unkey into their request path, our latency directly impacts their users' experience. We knew we needed to be fast, but serverless was fighting us every step of the way.
The Caching Problem
The fundamental issue was caching. In serverless, you have no guaranteed persistent memory between function invocations. Every cache read requires a network request to an external store, and that's where things got painful. We still used the global scope trick to cache some data across invocations, but the hit rates were very low.
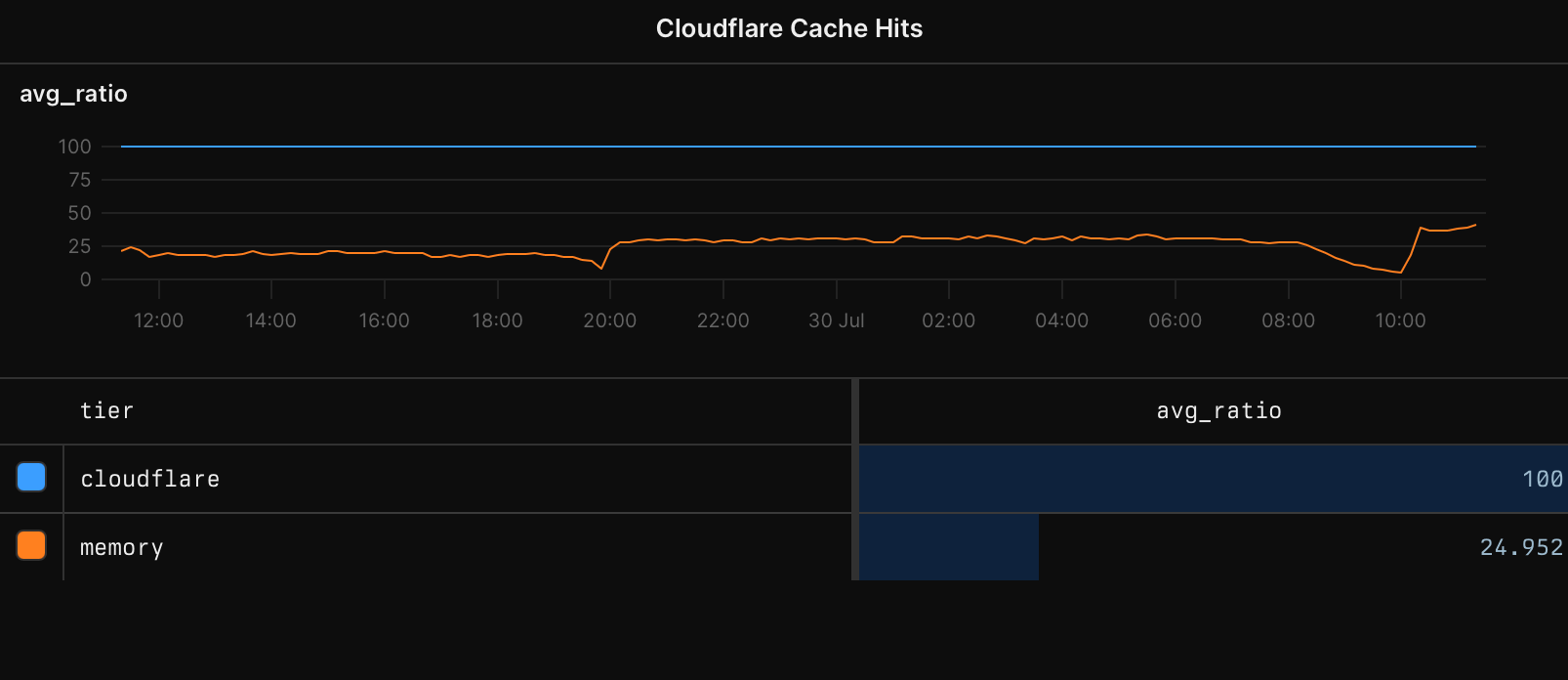
And while Cloudflare's cache had a very good hit rate, the latency was just not acceptable. It consistently took 30ms+ at p99 for cache reads. That's not necessarily terrible if you compare it to other networked caches, but when you're trying to build a sub-10ms API, it's a showstopper.
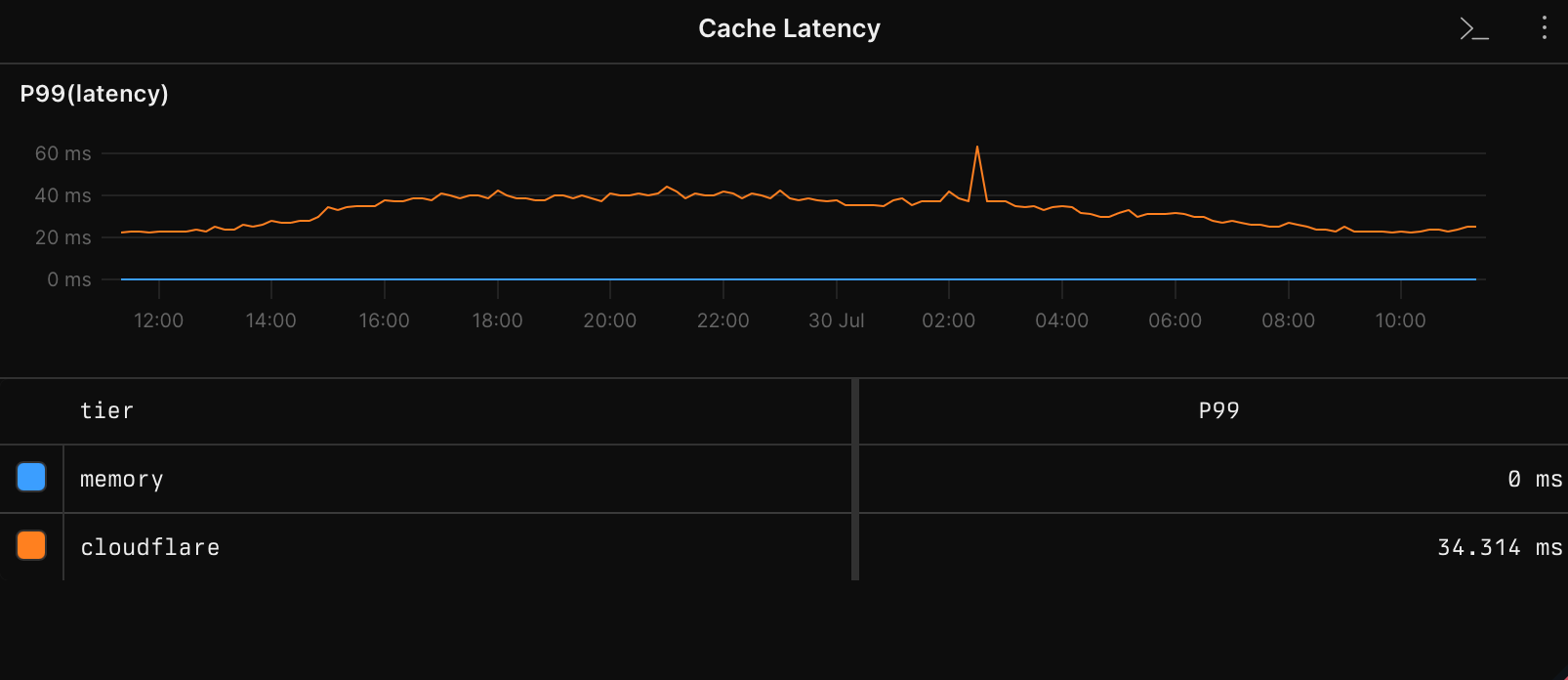
Our caching strategy used SWR across multiple tiered caches, but here's the thing: zero network requests are always faster than one network request. No amount of stacking external caches could get us around this fundamental limitation.
The SaaS Glue Problem
Serverless promised everyone you wouldn't need to worry about operations, it just works. And for the actual function execution that was indeed our experience too. Cloudflare Workers themselves were very stable. However, you end up needing multiple other products to solve artificial problems that serverless itself created.
Need caching? Add Redis. Need batching? Add a Queue and downstream handler. Need real-time features? Add Something. Each service adds latency, complexity, and another point of failure in addition to charging you for their services.
What's frustrating is that these aren't inherent technical challenges but limitations imposed by the serverless model. In a traditional server, you'd have all of these capabilities built-in or easily accessible without network hops.
We ended up having to use Cloudflare Durable Objects, Cloudflare Logstreams, Cloudflare Queues, Cloudflare Workflows and then actually some homemade stateful servers on top of that.
We found ourselves constantly evaluating and integrating new SaaS products, not to add business value, but just to work around the constraints of our chosen architecture. Many "simple" features required researching vendors, comparing pricing, handling authentication for yet another service, and debugging network issues between systems we don't control.
The Data Pipeline Nightmare
Performance wasn't our only problem. Getting data out of serverless functions was equally challenging.
The Batching Problem
Our API emits events for every key verification, rate limit, and API call. In traditional servers, you'd batch these events in memory and flush them periodically. In serverless, you have to flush on every single function invocation because the function might disappear after handling the request.
This led us to build an elaborate and overly complex pipeline:
For Analytics Events:
We built chproxy specifically because ClickHouse doesn't like thousands of tiny inserts. It's a Go service that buffers events and sends them in large batches. Each Cloudflare Worker would send individual analytics events to chproxy, which would then aggregate and send them to ClickHouse.
For Metrics and Logs:
To get metrics and logs out of Cloudflare Workers and into Axiom, we couldn't just send them directly because Axiom would sometimes reject them due to rate limits. We had to build a buffering service that would aggregate logs and metrics before sending them to Axiom without breaking the bank. Initially we thought we could just use Cloudflare Queues, but it would've been way too expensive. I think it was around trippling our current costs just to add queues.
Our metrics became elaborate JSON logs that Cloudflare would capture, then we had another worker acting as logdrain consumer. The consumer worker would parse the payload from Cloudflare, split the metrics events from log events and then send them off to Axiom.
We essentially built a distributed event processing system with multiple failure points just to work around serverless limitations.
The Solution: Stateful Simplicity
When we decided to rebuild our API in Go for v2, the difference was immediately obvious. Instead of that complex pipeline, we could just batch events in memory and flush directly every few seconds or whenever the buffer reached a certain size.
That's it. No auxiliary services, no complex log pipelines, no coordination. Just straightforward batching that any server application would do.
Performance Results
Being easier to operate or think about is one thing, but not really what our users care about. They care about performance. So how much faster is it?
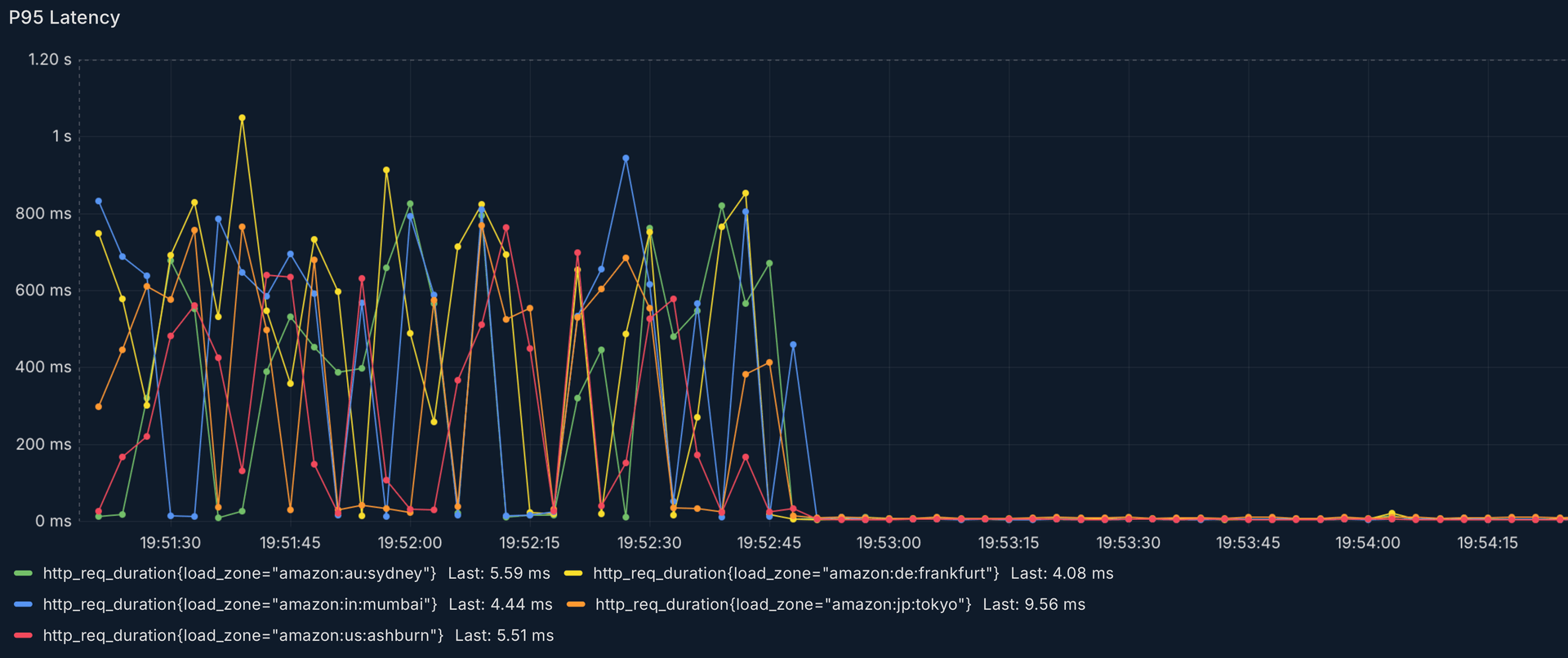
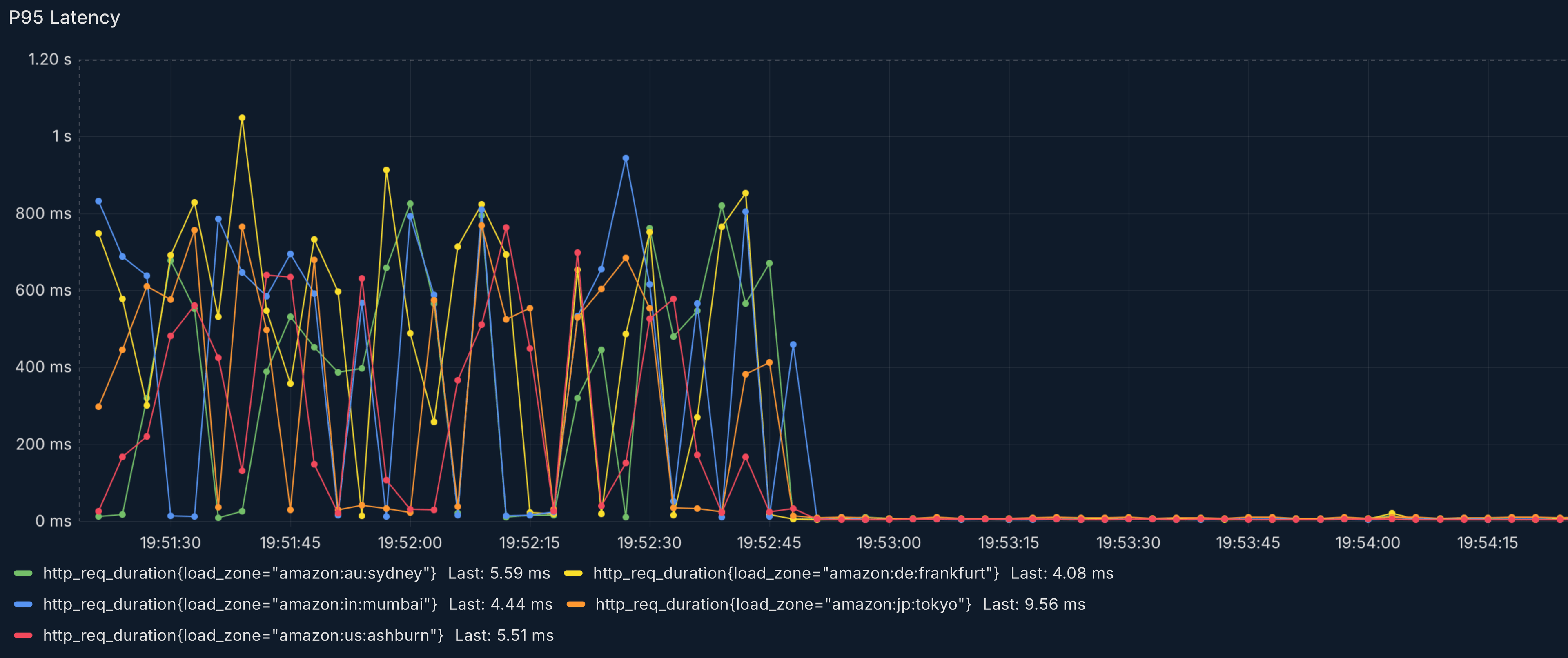
We tested calling our /v1/keys.verifyKey endpoint from multiple regions and then switching over to /v2/keys.verifyKey. I think it's pretty easy to spot in the chart above.
Now you might say, it's kind of unfair to measure the latency from the same cloud provider as where the API runs. However that's where most of our customers are located too. So maybe this is an unfair comparison, but it accurately reflects the reality of our users' experiences. It's worth noting that the v1 API runs in over 300 POPs around the world and has datacenters in each of those regions as well.
Strategic Benefits Beyond Performance
The move to stateful servers also unlocked other benefits.
Self-Hosting
Being tied to Cloudflare's runtime meant our customers couldn't self-host Unkey. While the Workers runtime is technically open source, getting it running locally (even in dev mode) is incredibly difficult.
With standard Go servers, self-hosting becomes trivial:
This isn't just about customer choice. It dramatically improved our own development experience. Developers can now spin up the entire Unkey stack locally in seconds, making debugging and testing infinitely easier.
Developer Experience Transformation
The complexity tax of serverless was affecting our entire team. Every new feature required thinking about:
- How to work around function limits
- How to handle data persistence between invocations
- How to debug issues across distributed log pipelines
- How to test locally with Cloudflare-specific APIs
Platform Independence
Perhaps most importantly, we're no longer locked into Cloudflare's ecosystem. We can deploy anywhere, use any database, and integrate with any third-party service without worrying about runtime compatibility.
Migration Strategy and Lessons
We used the migration as an opportunity to fix API design issues that had accumulated over time. The new v2 API runs alongside the old v1, and customers can use both during the deprecation period.
The one advantage of keeping serverless around? It doesn't cost us much to keep the v1 API running as usage dwindles to zero. We're essentially getting a free migration period.
What We Kept
We didn't throw out everything about our serverless approach:
- Global edge deployment: We're using AWS Global Accelerator to maintain low latency worldwide
- Automatic scaling: Fargate handles scaling for us without the serverless constraints
Rate Limiter Performance Boost
One area where the improvement has been particularly dramatic is our rate limiter. In the serverless model, we had to make significant tradeoffs between speed, accuracy, and cost. The distributed nature made achieving all three nearly impossible.
With stateful servers and in-memory state, we've been able to build a rate limiter that's faster, more accurate, and actually reduces our operational costs. We'll dive deep into this in a future post.
When Serverless Makes Sense (And When It Doesn't)
This isn't an anti-serverless post. Serverless is fantastic for many use cases:
- Infrequent workloads: When you're not running consistently, the scaling-to-zero economics are unbeatable
- Simple request/response patterns: When you don't need persistent state or complex data pipelines
- Event-driven architectures: Serverless excels at responding to events without managing infrastructure
But serverless struggles when:
- You need consistent low latency: External networked dependencies kill performance
- You require persistent state: Working around statelessness creates complexity
- You have high-frequency workloads: The per-invocation model becomes expensive
- You need fine-grained control: Platform abstractions can become limitations
The Complexity Tax
The biggest lesson from our migration is understanding the complexity tax of working around platform limitations.
In serverless, we built:
- A sophisticated caching library to work around statelessness
- Multiple auxiliary services for data batching
- Complex log pipelines for metrics collection
- Elaborate workarounds for local development
In stateful servers, all of that disappeared. We went from a distributed system with many moving parts to a straightforward application architecture.
Sometimes the best solution isn't to work around limitations but to choose a different foundation.
What's Next
We're currently running on AWS Fargate behind Global Accelerator, but this is temporary. Next year, we're launching "Unkey Deploy", our own deployment platform that will let customers (and us) run Unkey anywhere they want.
The move to stateful Go servers was the first step in making Unkey truly portable and self-hostable. Stay tuned for more details on that front.
Want to see the implementation details? Both our serverless and stateful APIs are open source in our GitHub repository. The serverless version is in apps/api/ and the new Go version is in go/apps/api/.
